




Indice di Gravità Covid-19: alcuni chiarimenti sulla metodologia
Il nostro indice di gravità sull’epidemia di Coronavirus ha destato grande attenzione e anche alcune critiche: le nostre risposte nel merito.
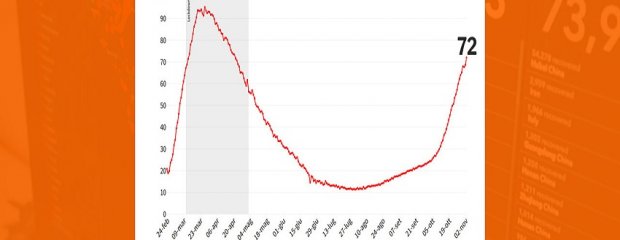
Nelle scorse settimane, YouTrend ha iniziato a pubblicare un Indice di Gravità dell’epidemia di Covid-19 in Italia, che ha ottenuto grande attenzione tanto sui media quanto sui social network. Lo scopo dell’indice, vale la pena ricordarlo, era fornire un numero univoco e comprensibile per valutare lo stato e l’andamento della situazione epidemica italiana. In altre parole, l’obiettivo era offrire anche a chi non avesse una conoscenza dettagliata del bollettino quotidiano una chiave di lettura integrativa, comprensibile e confrontabile nel tempo.
Quello che non pensavamo di ottenere, invece, era un’unità di misura risolutiva per la descrizione della pandemia in grado di sostituire una valutazione epidemiologica accurata. Il Covid-19 è una malattia sulla quale esiste una conoscenza scientifica ancora parziale, e ancor più frammentaria è la disponibilità di dati pubblici e dettagliati relativi all’Italia. In seguito al lancio, forse anche per un fraintendimento di questi obiettivi, l’Indice di Gravità Covid-19 ha raccolto anche alcuni dubbi e critiche. Fra queste spiccano quelle mosse da un professore di economia dell’Università di Pavia, Riccardo Puglisi, che meritano risposte puntuali.
I dubbi sull’Indice di Gravità Covid-19
I dubbi avanzati dal prof. Puglisi possono essere riassunti così:
- Perché l’IFR (Infection Fatality Rate, cioè il tasso di decessi sul totale dei casi reali di contagio) del Covid-19 viene considerato costante nel tempo?
- Come mai, nella composizione dell’indice di gravità Covid-19, l’indice parziale dei contagi viene pesato allo stesso modo dell’indice parziale dei decessi?
- Perché si è scelto di utilizzare la radice quadrata della media dei tre indici parziali, anziché utilizzare direttamente una media aritmetica o ponderata?
Eccoci quindi a rispondere nel merito alle tre domande: proveremo non solo a spiegare il motivo di queste tre scelte che abbiamo preso nella costruzione dell’indice, ma anche il ragionamento e le alternative che avevamo formulato in quella fase.
L’IFR nell’Indice di Gravità Covid-19
Come accennavamo in precedenza, molte certezze sul Covid-19 ancora oggi mancano, ed esiste un discreto dibattito sia sull’IFR che sulla sua evoluzione. La scelta di tenerlo “fisso” da marzo è dovuta al fatto che non riteniamo vi sia un sufficiente consenso in letteratura per affermare che questo sia cambiato in modo significativo rispetto alle stime precedenti. Vi sono dati positivi ed incoraggianti (come lo studio di Cicero et al. 2020, a cui ha partecipato anche il prof. Puglisi, che riguarda però una fascia specifica, i decessi in T.I., in uno specifico ospedale), ma non sappiamo quanto di questi risultati sia dovuto a migliori trattamenti, minor carico sul SSN, minore carica virale (legata magari a fattori quali l’arrivo della primavera) o altri ancora.
In questa situazione, la scelta è stata quella di appoggiarsi il meno possibile sull’IFR e su dati di stima. È infatti doverosa una precisazione: l’indice non prevede i decessi (cosa su cui fallirebbe, essendo l’attuale CFR laggato superiore all’IFR) ma ipotizza, a partire dai decessi riscontrati nelle settimane precedenti, i casi plausibili. L’IFR non interviene né sull’indice di stress del sistema sanitario né su quello di mortalità: serve a capire quanto corretta sia la fotografia dell’epidemia ‘oggi’ rispetto ad un picco, quello di marzo, che stimiamo essere molto più alto di quello registrato dalla Protezione Civile (sul singolo giorno si tratta di un valore circa 15 volte superiore) e che usiamo come valore “peggiore” sul singolo giorno. Tra i vari IFR presentati, abbiamo optato per il Verity, usato anche in altri studi (come quello di Matteo Villa) e che si è comunque rivelato inferiore all’IFR stimato dall’indagine sierologica ISTAT.
In altre parole, per come è attualmente costruito l’indice, rispetto all’ISTAT, stiamo sovrastimando il numero di casi registrati in primavera: registriamo come valore di riferimento per l’indice parziale dei casi un punto più alto di quello effettivamente verificatosi. Inoltre, se davvero l’IFR ha subito una significativa frenata, come tutti speriamo, oggi stiamo sottostimando (e non sovrastimando!) i casi plausibili e quindi valutando troppo positivamente la nostra capacità di fare contact-tracing. È una scelta perfetta? No, certo: avessimo dati certi e sicuri, vi fosse unanimità o almeno una posizione di consenso che vada al di là del “è plausibile che l’IFR sia migliorato”, potremmo stimare con relativa precisione quanti casi abbiamo perso e quindi quanti nuovi decessi e quale peso sul SSN attenderci nei 7-14 giorni seguenti.
Come sappiamo, però, non possiamo contare su questo tipo di informazioni. La scelta, quindi, è quella di usare l’IFR solamente ‘a ritroso’ e solo nello specifico contesto dei casi calcolati. Per la mortalità, nonostante il dato dei decessi sia in ritardo sull’andamento dell’epidemia, lasciamo che siano i dati ufficiali ‘a parlare’.
Quale ponderazione utilizzare?
L’indice parziale dei casi pesa come gli altri due indicatori perché è l’indicatore con minore ritardo tra quelli che abbiamo a disposizione. Sappiamo che un aumento di casi si tradurrà molto probabilmente in un aumento di ospedalizzati/decessi nel giro di due settimane, per quanto non sappiamo con esattezza sino a quale livello. In assenza di informazioni tempestive che permettano di stratificare i nuovi contagi per età e di un IFR condiviso a partire dal quale stimare i decessi che seguiranno ai nuovi casi, questi sono i dati a disposizione.
Come sappiamo, sia le ospedalizzazioni che i decessi sono in ritardo rispetto al progredire dell’epidemia. Non ci sembra francamente allarmistico, quindi, considerare l’indice dei casi alla pari degli altri due che sono, di fatto, in questo momento sottopesati nella loro gravità, rappresentando un momento antecedente. Per paradosso, quando usciremo dall’attuale emergenza, la critica potrebbe tranquillamente essere quella opposta: “bisogna dare più valore ai casi (in discesa) perché i decessi rappresentano un periodo arretrato e da ora in avanti ci saranno meno morti e meno ricoveri”.
Qual è la curva corretta per l’indice di gravità del Covid-19?
La scelta di usare la radice quadrata è a nostro avviso un buon modo per modellare l’andamento del rischio in un’epidemia. Il nostro punto di partenza è il seguente: non riteniamo che il rischio sia funzione lineare della curva epidemica. Questo tende a sottostimare quanto rapidamente le cose possono peggiorare: un po’ perché nella fase iniziale di un’epidemia è difficile distinguere tra incremento lineare ed esponenziale, un po’ perché, ragionando più ‘socialmente’, esiste un lag tra l’implementazione di policies di contenimento ed il loro effetto. L’utilizzo della radice quadrata serve a questo: c’è una crescita inizialmente più rapida, che si avvicina via via ad una progressione lineare.
Chiaramente non si tratta dell’unica trasformazione alla quale abbiamo pensato. La prima e più e più ovvia ci è sembrata una logistica, che da sempre descrive l’andamento di qualsiasi epidemia (e quindi, nel nostro ragionamento iniziale, anche l’andamento del rischio connesso ad un’epidemia). Abbiamo visto abbastanza in fretta che non funzionava, in buona parte perché richiedeva la scelta di vari parametri, aggiungendo ulteriore arbitrarietà. Un’alternativa alla quale abbiamo pensato era una trasformazione logaritmica ‘normalizzata’ sul modello di quella utilizzata per la salienza in Prosser[1]: di nuovo, questo nell’idea che nelle fasi iniziali dell’epidemia una progressione lineare sottostimi l’andamento del rischio; anche in questo caso, però, i risultati erano deludenti perché risultavano troppo poco distanziati tra di loro il punto di minimo e quello di massimo. La radice quadrata ci è quindi sembrata approssimare in maniera migliore quello che, per noi, è l’andamento del rischio in un’epidemia.
Che effetto hanno queste differenze?
A quanto detto sopra vorremmo aggiungere anche qualche altra considerazione. In primo luogo, l’indice è calcolato sempre in maniera identica per tutta la lunghezza della curva epidemica e permette quindi di fare dei confronti. La confrontabilità dell’indice fra diversi periodi è fra le prime priorità che abbiamo scelto di perseguire durante la sua costruzione: si vede per esempio a vista d’occhio che la situazione si degrada ad un ritmo inferiore a quello di marzo scorso. Certo: ogni indice è criticabile ed è normale quando si sintetizzano informazioni/tendenze diverse ed a volte contrastanti.
Si può criticare, per esempio, anche come troppo conservativo: non consideriamo il fatto che, se davvero l’epidemia di coronavirus soffre di ‘stagionalità’, il fatto di avere i numeri attuali a inizio novembre è peggio che averli all’11 marzo con la primavera vicina. Non consideriamo che l’effetto marginale delle policies che restano a disposizione del governo è ridotto: in altre parole, un lockdown oggi avrebbe un effetto sulla curva probabilmente inferiore a quello di marzo, perché banalmente molte politiche di contenimento sono già in atto. Non consideriamo il rischio che il COVID si sovrapponga alla stagione influenzale.
L’Indice di Gravità Covid-19 è troppo allarmistico?
Se le critiche le accettiamo e le consideriamo, più difficili da mandare giù sono le accuse sulla malafede legate a un presunto eccesso di “allarmismo”: la nostra metodologia è trasparente e, essendo basata su dati a loro volta pubblicamente accessibili, replicabile. Avessimo voluto fare “allarmismo”, avremmo potuto facilmente fare cherry-picking. Ecco qualche esempio facile:
- Avremmo potuto non considerare il fatto che l’aumento dei casi registrati è legato ad una migliore capacità di testing e confrontare brutalmente i casi di oggi con quelli di marzo/aprile (l’indice ‘lineare’ sarebbe superiore a quello attuale).
- Avremmo potuto non considerare le variabili di trend le quali già in fase di gestazione dell’indice si dimostravano ‘migliori’ rispetto ai primi di marzo. Basta focalizzarsi solo sull’occupazione delle TI e dei ricoveri ospedalieri e si ottiene un dato significativamente più preoccupante.
- Avremmo potuto scegliere un valore massimo più “basso” per i singoli indicatori. Per intenderci, il valore pari a 100 per ciascun indicatore è fissato in alto, al rispettivo valore massimo della prima ondata. Per essere a 100 tutti gli indici devono essere identici o superiori al picco di marzo, ovvero dovremmo avere un tasso di occupazione di UTI e un numero di casi plausibili, di ricoverati in area medica e decessi come al picco di ognuna di queste variabili e, giacché includiamo i dati di trend, in peggioramento ad una velocità maggiore di quella riscontrata nel giorno peggiore di marzo. Abbiamo, insomma, fissato l’asticella molto in alto, anche per evitare che il nostro indice potesse creare un allarme ingiustificato.
Fare informazione su una pandemia in atto non è facile: vi è sempre il rischio di sottostimare/sovrastimare qualcosa. Il nostro compromesso ci pare accettabile, ma soprattutto è trasparente e per questo permette di non essere d’accordo.
[1] Prosser, Christopher. 2015. ‘Dimensionality, Ideology and Party Positions towards European Integration’. West European Politics: 1–24.
Lasciare un commento
Per commentare registrati al sito in alto a destra di questa pagina
Se non sei registrato puoi farlo qui
Sostieni la Fondazione AgoraVox

