



Calcolatori e codifiche

Quando ho parlato di calcolatori e alfabeti ho barato. Più precisamente, ho omesso di parlare dei vari insiemi di caratteri che assomigliavano vagamente all’ASCII, nel senso che lettere e numeri stavano al loro posto, ma altri caratteri no. Chi è vecchio come me forse ricorda ancora l’Apple ][, con i suoi caratteri in negativo (ma solo maiuscoli! O erano quelli lampeggianti? Chi se lo ricorda più...) Chi ha giusto qualche anno in meno, invece, dovrebbe riuscire a ricordarsi il font semigrafico dei primi PC IBM: la cosiddetta "code page 437", che per mezzo di magheggi vari, permetteva anche di usare le posizioni riservate ai caratteri di controllo per fare le cornicette. E comunque Windows aveva la sua propria codifica a otto bit, Windows-1252 (no, non ne avevano provate altre 1251! Semplicemente, i vari Windows 125x corrispondono logicamente agli ISO-8859-y, e permettono di scrivere in alfabeti diversi da quelli latini standard). Anche Apple andava avanti per conto proprio, e fino a OS X aveva il suo charset, Mac OS Roman. Ma, anche ora, che siamo più o meno tutti d'accordo a usare Unicode in una versione o nell'altra non è che le cose funzionino così bene.
Iniziamo per esempio a prendere la vecchia codifica UCS-2: in pratica, la prima versione di Unicode con 65536 caratteri (due byte), che sarebbero stati sufficienti per qualunque alfabeto. La codifica di per sé è semplicissima: ogni carattere occupa due byte, e a ogni coppia di byte corrisponde un carattere. Magari il font che si sta usando non possiede quel carattere, e a video ci appare un rettangolino vuoto, o il carattere, oppure un numerino esadecimale; ma questi sono problemi secondari, visto che con ogni probabilità se non abbiamo il font giusto, non sapremo comunque leggere il testo, e comunque se lo inviamo a qualcun altro, magari lui o lei saprà leggerlo. Tutto perfetto, vero? Quasi. In che ordine vengono salvati questi due byte in un computer? Non è dato saperlo: dipende dall’architettura hardware, insomma da come, chi ha progettato la CPU, trovava più comodo fare per fare arrivare i byte alle varie unità logiche. In inglese è stato persino coniato un termine apposito, “endianness”, tanto per dire. Il modo “big endian”, che è quello che usa Internet negli standard e usava Motorola nei suoi chip, è quello più naturale: i bit sono tutti nell’ordine giusto. Il modo “little endian”, usato da Intel invece mette a sinistra il byte meno significativo, e quindi il numero 256 non si scrive come 00000001.00000000 ma come 00000000.00000001. Occorre pertanto trovare un modo per capire se l’ordine dei byte è quello che serve oppure no; XML se la cava perché i suoi file iniziano sempre con i caratteri <? e quindi può guardarli, altri si arrangiano.
Come se non bastasse, una codifica come UCS-2 per un testo in una lingua occidentale spreca metà dello spazio, che costa poco ma è comunque scomodo. Così si è pensato a una codifica dei caratteri a lunghezza variabile: ci sono caratteri “fortunati” e meno fortunati. Il formato UTF-8 è proprio fatto così. Il trucco è molto semplice: si codificano i caratteri in questo modo. (U+nnnn è il modo che usa Unicode per definire il numero d’ordine dei caratteri, per la cronaca; ricordatevi però che nnnn non è un numero decimale, ma esadecimale)
- Se il carattere ha codice tra 0 e 127, cioè tra U+0000 e U+007F, bastano sette bit per definirlo; si mette l’ottavo bit a zero e si usa un solo byte per definirlo.
- Se per definire il carattere occorrono da 8 a 11 bit, cioè si va da U+0080 a U+07FF, si dividono i bit come 5+6; si fa iniziare il primo byte (logico) con i bit 110 e il secondo con 10.
- Se occorrono da 12 a 16 bit, cioè si va da U+0800 a U+FFFF, si dividono i bit come 4+6+6; si fa iniziare il primo byte (logico) con i bit 1110 e gli altri con 10.
- Se occorrono da 17 a 21 bit, cioè si va da U+10000 a U+1FFFFF, si dividono i bit come 3+6+6+6; si fa iniziare il primo byte (logico) con i bit 11110 e gli altri con 10.
Di per sé la specifica arrivava fino a 31 bit, ma visto che UTF-16 si è fermato a 21 bit (sempre per la solita storia “ventun bit saranno sufficienti per qualunque alfabeto”) attualmente la codifica si ferma qui.
Notato nulla di particolare? Se andiamo a leggere, in un punto a caso, uno stream di byte in UTF-8, se il byte inizia per 10 sappiamo che siamo a metà di un carattere, e possiamo spostarci indietro al più di tre byte per trovare il suo inizio. Insomma, non rischiamo di avere un guazzabuglio illeggibile. Inoltre, non appena troviamo il primo byte che inizia con 1, se il secondo bit è 0 sappiamo che abbiamo un testo little endian, mentre se è 1 il testo è big endian. In Microsoft, però non sono mai stati troppo sicuri che la cosa funzionasse, così molti programmi, come per esempio Notepad, attaccano i tre byte 0xEF, 0xBB, 0xBF all’inizio di ogni file. Questi byte codificano il cosiddetto BOM, “Byte Order Mark”, che è un carattere Unicode come tutti gli altri; guardando l’ordine dei byte nel file, è facile vedere se siamo in big endian o little endian.
Come ho detto, una codifica variabile va bene per noi occidentali: a parte i fortunatoni degli inglesi, i cui caratteri sono tutti codificati con un byte, ne bastano comunque due per gli alfabeti latino, greco, cirillico, ebraico, arabo e per i segni diacritici. Ci sono casi sfortunati, come il simbolo dell’euro € che ha bisogno di tre byte; però ci si può accontentare. Giapponesi, cinesi e coreani no: e non è un caso che loro prediligano, spesso, altre codifiche non standard ma più egualitarie (UTF-16 andrebbe loro bene, ma perché modificare quello che già funzionava loro da anni? e comunque, se proprio serve, lo standard giapponese JIS X 0221-1:2001 è equivalente a ISO 10646-1:2000)
Mi fermo qua, lasciandovi in contemplazione della tabella “Character Encodings” che si trova nella Wikipedia in lingua inglese… giusto per capire come il bello degli standard è che ce ne sono così tanti tra cui scegliere!
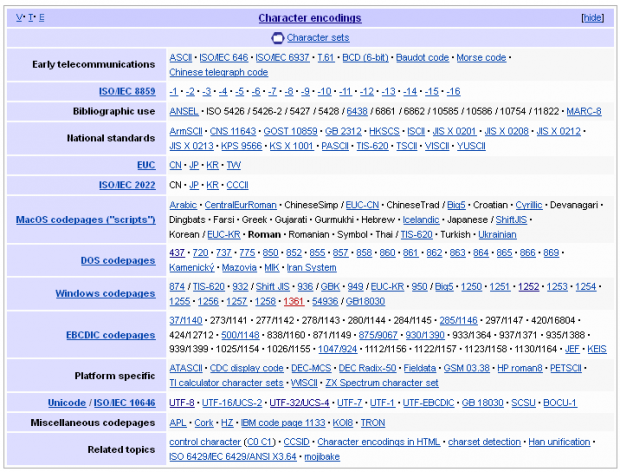
Pagina di Wikipedia sui caratteri.
Di .mau.
Questo articolo è stato pubblicato quiLasciare un commento
Per commentare registrati al sito in alto a destra di questa pagina
Se non sei registrato puoi farlo qui
Sostieni la Fondazione AgoraVox

