 AgoraVox Italia
AgoraVox Italiahttp://www.geosmartmagazine.it
Articoli
-
Circular City Forum 2026 a Genova: città e economia circolare
20 marzo, di Dario SchimizziDal 17 al 22 aprile 2026 Genova ospiterà la seconda edizione del Circular City Forum Genova 2026, un evento dedicato alla sostenibilità urbana, all’economia circolare e all’innovazione territoriale.
La rassegna, promossa dal Comune di Genova nell’ambito del progetto C-City – Genova Città Circolare, riunirà istituzioni, imprese, ricercatori e cittadini per confrontarsi sulle nuove strategie di sviluppo sostenibile per le città del futuro.
Durante il forum verrà presentata anche la Rete delle Città Circolari, un network pensato per rafforzare la collaborazione tra amministrazioni locali impegnate nella transizione ecologica e nella gestione sostenibile dei sistemi urbani.
Circular City Forum Genova 2026: un evento dedicato all’economia circolare
Il Circular City Forum Genova 2026 nasce come evoluzione del precedente Circular Value Forum, ampliando il programma e la durata dell’evento per offrire una piattaforma di confronto ancora più ampia sui temi della sostenibilità.
Nel corso delle sei giornate saranno affrontati numerosi temi strategici per il futuro delle città:
- economia circolare
- blue economy
- gestione sostenibile degli spazi urbani
- tutela delle risorse idriche
- responsabilità sociale d’impresa
- innovazione tecnologica
- moda sostenibile e riuso dei materiali
- filiere alimentari sostenibili
L’obiettivo è favorire un dialogo concreto tra pubblica amministrazione, mondo produttivo e ricerca scientifica, creando nuove opportunità di collaborazione e sviluppo.
La Rete delle Città Circolari
Uno dei momenti centrali del Circular City Forum Genova 2026 sarà la presentazione della Rete delle Città Circolari, una piattaforma permanente di confronto e cooperazione tra amministrazioni locali.
Il network consentirà di:
- condividere strumenti e politiche per la sostenibilità urbana
- sviluppare progetti comuni tra città italiane ed europee
- promuovere modelli di economia circolare replicabili
- coordinare iniziative istituzionali sul tema della transizione ecologica
La rete nasce all’interno del progetto C-City – Genova Città Circolare, integrato nell’Action Plan Genova 2050 e nella strategia Lighthouse – Genova Città Faro.
Il progetto è stato riconosciuto dal programma europeo URBACT come una best practice europea nel campo dell’economia circolare.
Eventi e networking al Circular City Forum Genova 2026
Rispetto alla prima edizione, il Forum cresce notevolmente sia per durata sia per contenuti.
Le attività congressuali si svolgeranno principalmente presso:
Accanto agli incontri istituzionali e ai panel di approfondimento, il programma prevede numerose attività esperienziali e di networking.
Tra le iniziative più attese:
Contest e iniziative
- Food contest con scuole alberghiere e chef professionisti dedicati alla cucina sostenibile
- Eco-fashion show, una sfilata dedicata alla moda sostenibile e al riuso creativo dei materiali
- Expo di prodotti artigianali a filiera corta per valorizzare le eccellenze locali
- Startup contest per promuovere nuove imprese innovative nel settore della sostenibilità
Queste iniziative puntano a coinvolgere attivamente imprese, studenti, professionisti e cittadini nella costruzione di un modello urbano più sostenibile.
Genova laboratorio nazionale di economia circolare
Secondo l’assessora all’ambiente e alla sostenibilità Silvia Pericu, l’evento rappresenta un passaggio strategico nel percorso che punta a trasformare Genova in un laboratorio nazionale permanente di economia circolare.
L’obiettivo è sviluppare un modello urbano innovativo basato su tre pilastri:
- innovazione industriale
- tutela ambientale
- coesione sociale
Attraverso il dialogo tra istituzioni, imprese e comunità educative, la sostenibilità può diventare un’infrastruttura concreta dello sviluppo economico e sociale.
La transizione ecologica, se guidata da politiche pubbliche lungimiranti e da una responsabilità condivisa, può infatti generare nuove opportunità economiche, migliorare la qualità della vita urbana e creare filiere produttive sostenibili radicate nel territorio.
Chi organizza il Circular City Forum Genova 2026
Il Circular City Forum Genova 2026 è promosso dalla Direzione Attrattività, Competitività e Transizione Ecologica del Comune di Genova nell’ambito del progetto C-City.
L’evento è organizzato in collaborazione con la Camera di Commercio di Genova e con il supporto organizzativo di Clickutility Team.
Il forum segue inoltre le linee guida di sostenibilità del Comune di Genova per l’organizzazione di eventi sia indoor sia outdoor.
Per maggiori informazioni visita il sito ufficiale.
(Fonte: Circular City Forum 2026)
Leggi anche:
- Inaugurato il nuovo Smart City Lab Milano
- Smart City Roma: presentati i progetti per la città sostenibile
- Progetto C-City: a Genova primo evento sulle città circolari in Italia
- Inaugurato il nuovo Smart City Lab Milano
L'articolo Circular City Forum 2026 a Genova: città e economia circolare proviene da Geosmart Magazine.
-
Le otto grandi famiglie di Intelligenza Artificiale
19 marzo, di Sarino Alfonso GrandeLe famiglie di intelligenza artificiale non sono tutte uguali: alcune servono a comprendere e generare testo, altre a leggere immagini e video, altre ancora a compiere azioni o a segmentare oggetti. Capirle bene aiuta a scegliere il modello giusto e a costruire applicativi davvero utili.
Quando si parla di AI, spesso si fa l’errore di usare un’unica etichetta per tecnologie molto diverse tra loro. In realtà esistono varie famiglie di intelligenza artificiale, e ciascuna ha punti di forza, limiti e contesti d’uso specifici. Alcune sono nate per lavorare sul linguaggio, altre sulla visione artificiale, altre ancora sull’automazione operativa o sulla segmentazione delle immagini. Per chi sviluppa applicativi reali, questa distinzione non è teorica: è una scelta che incide direttamente su costi, qualità, stabilità e tempi di progetto.
Le principali famiglie di intelligenza artificiale che oggi ricorrono più spesso sono LLM, LCM, LAM, MoE, VLM, SLM, MLM e SAM. Non tutte indicano la stessa cosa: alcune sono famiglie vere e proprie di modelli, altre descrivono un approccio architetturale, altre ancora rappresentano direzioni di ricerca emergenti. Il punto fondamentale è che non si tratta di prodotti tutti equivalenti o in competizione diretta sullo stesso piano.
Nei progetti più seri, infatti, non si sceglie una sola AI “che faccia tutto”, ma si costruisce una filiera in cui ogni modello svolge la parte che gli riesce meglio. Un modulo visivo può leggere una scena, un sistema di segmentazione può isolare il target, un OCR può estrarre testo, un modello linguistico può trasformare l’output in una scheda leggibile e un agente operativo può infine scrivere tutto in un database o in un gestionale.
In questo articolo vedremo le famiglie di intelligenza artificiale in modo pratico e con un taglio operativo. L’obiettivo è chiarire a cosa servono, chi le può usare, come si producono e come possono entrare davvero in progetti concreti come il riconoscimento della segnaletica stradale da dashcam, la lettura di codici a barre da drone, la catalogazione di pannelli fotovoltaici o la generazione di commenti tecnici su mappe NDVI e altri indicatori vegetazionali.
I diversi livelli di intelligenza artificiale
L’infografica da cui prende avvio questo ragionamento è utile perché mostra a colpo d’occhio otto etichette che oggi compaiono spesso quando si parla di AI. Va però letta con attenzione. Alcune sigle sono ormai standard e molto diffuse, come LLM, VLM, SLM, MLM, MoE e SAM. Altre, come LCM o LAM, sono in parte più recenti, meno uniformi nell’uso o più legate a una certa fase dell’evoluzione del settore.
Per questo motivo, parlare di famiglie di intelligenza artificiale non significa elencare otto prodotti equivalenti, ma capire otto modi diversi in cui l’AI può intervenire in una pipeline. Alcune famiglie descrivono il “cosa fa” il modello, altre il “come è costruito”, altre ancora il “tipo di capacità” che si vuole ottenere. È proprio qui che spesso nasce la confusione.
Tabella rapida sulle famiglie di intelligenza artificiale
Famiglia AI Che cosa fa in una frase Chi la usa più spesso Esempio tipico LLM Capisce e genera testo Aziende, sviluppatori, consulenti Assistant, report, codice LCM Lavora su concetti più alti del token Ricerca, R&D Recupero semantico avanzato LAM Trasforma intenzioni in azioni Chi automatizza flussi Agenti che usano tool MoE Smista il lavoro fra più esperti Vendor di foundation model Modelli grandi più efficienti VLM Unisce immagini e linguaggio Computer vision, document AI, retail Analisi foto e video SLM Porta l’AI su device o edge Chi vuole costi bassi e privacy Classificatori locali MLM Predice parole mascherate e capisce contesto Search, NLP classico NER, classificazione SAM Segmenta oggetti in immagini e video Visione artificiale Ritaglio automatico del target Famiglie di intelligenza artificiale per il linguaggio: LLM
Quando si dice LLM, in sostanza si parla di modelli addestrati per lavorare molto bene con il linguaggio: capire istruzioni, riassumere, scrivere, tradurre, classificare, estrarre informazioni e generare testo utile. È la famiglia più nota perché è quella che l’utente incontra subito: chatbot, copiloti, assistenti, strumenti di scrittura e sistemi di supporto documentale.
Tra le famiglie di intelligenza artificiale, gli LLM sono particolarmente utili quando il problema finale ha una forte componente linguistica. Per esempio: compilare schede, produrre descrizioni coerenti, trasformare dati grezzi in testo leggibile, creare checklist, normalizzare campi, scrivere codice, costruire risposte ragionate o interrogare basi documentali.
Praticamente chiunque può usarli: dallo studio professionale che vuole produrre verbali e riepiloghi, fino all’azienda che costruisce assistenti verticali per procedure, ticketing, normativa o supporto interno. In genere si parte da un foundation model preaddestrato su grandi quantità di testo e codice, e poi si passa a una fase istruttiva con allineamento, fine-tuning, recupero documentale, guardrail, test e ottimizzazioni.
In uno scenario come Catasto Strade, un LLM non è il modello che “vede” il cartello. Quella parte la fanno meglio VLM, detector o OCR. L’LLM entra dopo: prende l’uscita tecnica, la trasforma in una scheda comprensibile, uniforma le descrizioni, riconosce casi incoerenti, suggerisce campi mancanti e aiuta a rendere il dato finale più pulito e spendibile.
Sul versante commerciale, oggi i nomi più citati sono le famiglie GPT di OpenAI, Claude di Anthropic e Gemini di Google. Sul versante open o open-weight i riferimenti più noti sono Meta Llama e vari modelli di Mistral AI.
Da ricordare: tra le famiglie di intelligenza artificiale, LLM vuol dire soprattutto linguaggio. Non è il miglior occhio del sistema, ma spesso è la miglior penna e il miglior normalizzatore.
Famiglie di intelligenza artificiale emergenti: LCM
LCM è una sigla meno consolidata rispetto a LLM. In questo articolo viene usata nel senso oggi più serio e documentato: Large Concept Models, cioè modelli che provano a ragionare non solo token per token ma anche a livello di concetti più alti, spesso rappresentati in uno spazio semantico di frase o di unità di significato.
Tra le famiglie di intelligenza artificiale, questa è una delle più promettenti quando il problema richiede una visione più concettuale del contenuto: recupero semantico, sintesi di blocchi informativi, passaggio da frasi a rappresentazioni più stabili, collegamento tra lingue o modalità diverse. In parole semplici, aiuta a lavorare meno sulla forma superficiale e più sul significato reale.
Oggi è una direzione interessante soprattutto per chi lavora in ricerca, R&D, retrieval avanzato, knowledge management multilingua, grandi archivi documentali o contenuti in cui il significato globale conta più del singolo termine. Nella pratica si parte da embedding robusti, corpora multilingua e obiettivi di training che privilegiano la coerenza di frase o di concetto.
Immagina un archivio di rilievi stradali o di report agricoli scritti in modo diverso da operatori diversi. Un LCM può aiutare a raggruppare descrizioni equivalenti anche se non usano le stesse parole: “segnale deteriorato”, “cartello usurato” e “pannello con pellicola degradata” possono essere ricondotti alla stessa problematica.
Tra i riferimenti più interessanti in ambito open c’è il lavoro pubblicato da Meta AI sui Large Concept Models.
Da ricordare: tra le famiglie di intelligenza artificiale, LCM è una frontiera più sperimentale. È utile conoscerla, ma conviene adottarla solo se il problema semantico è davvero centrale.
Famiglie di intelligenza artificiale che agiscono: LAM
LAM viene usato per indicare modelli o sistemi orientati non soltanto a capire una richiesta, ma a trasformarla in azione: cliccare, compilare, chiamare strumenti, muoversi dentro un’interfaccia, orchestrare passaggi. Più che produrre solo testo, il LAM fa succedere qualcosa.
Tra le famiglie di intelligenza artificiale, questa diventa utile quando il problema non finisce con una risposta sullo schermo. Per esempio: aprire un gestionale, estrarre campi, usare un software GIS, lanciare una procedura, interrogare servizi, rinominare file, creare pratiche, compilare moduli o pilotare un workflow di back office.
Può essere usata da studi tecnici, uffici amministrativi, aziende utility, società che fanno controllo qualità, manutenzione, logistica o document management. Nella pratica raramente si “addestra un LAM puro” da zero: più spesso si combina un modello forte su linguaggio e visione con un ambiente di strumenti, browser automation, API, funzioni, motori di pianificazione, vincoli, log, controlli umani e policy di sicurezza.
Nel tuo applicativo di catalogazione dei pannelli fotovoltaici da drone, un componente di tipo LAM può prendere il risultato del riconoscimento barcode, aprire il gestionale corretto, associare l’ID al pannello, verificare che il campo catastale o l’appezzamento siano coerenti, creare la scheda e gestire le eccezioni con revisione umana.
Sul mercato queste soluzioni vengono spesso presentate come agenti operativi, computer use o browser automation. In ambito commerciale rientrano servizi che permettono al modello di usare interfacce e tool. In ambito open sono diffusi framework e librerie agentiche.
Da ricordare: tra le famiglie di intelligenza artificiale, LAM non sostituisce la progettazione del processo. Senza regole, log e supervisione può compiere azioni sbagliate molto più in fretta.
Famiglie di intelligenza artificiale e architetture: MoE
MoE, cioè Mixture of Experts, non è una famiglia separata come VLM o SAM, ma una scelta architetturale. L’idea è semplice: invece di far lavorare sempre tutto il modello allo stesso modo, si usano più sottoreti specializzate e un meccanismo di routing decide quali attivare per ciascun input. In questo modo si cerca di aumentare capacità ed efficienza allo stesso tempo.
Tra le famiglie di intelligenza artificiale citate più spesso, MoE è quella che va letta come un “come è costruito il modello”, più che come un tipo di funzione finale. Serve soprattutto per scalare: è utile quando si vuole più capacità mantenendo tempi e costi più efficienti rispetto a un grande modello denso attivato per intero.
La usa soprattutto chi sviluppa foundation model o chi sceglie modelli già costruiti con questa architettura. Per l’utente finale è utile conoscerla perché aiuta a capire perché alcuni modelli risultino più efficienti o più rapidi a parità di prestazioni.
In una pipeline stradale nazionale, un modello MoE può essere utile dietro le quinte per gestire in modo più efficiente sottocompiti diversi, come testi, immagini, segnali o pattern specifici. Ma è una questione che resta soprattutto “sotto il cofano”.
Da ricordare: tra le famiglie di intelligenza artificiale, MoE non è qualcosa che l’utente usa da sola, ma una scelta di progettazione che può rendere i modelli più grandi e più efficienti.
Famiglie di intelligenza artificiale per immagini e video: VLM
VLM significa Vision Language Model. È una delle famiglie oggi più interessanti perché mette insieme due mondi: visione e linguaggio. In pratica il modello non si limita a descrivere un’immagine, ma cerca di collegare ciò che vede a una rappresentazione testuale utile, interrogabile e contestualizzata.
Tra le famiglie di intelligenza artificiale, questa è particolarmente preziosa quando bisogna lavorare con foto, video, documenti visivi, dashcam, droni, scene urbane, scaffali, pannelli tecnici o immagini satellitari e aeree. Serve per capire meglio la scena, dare un significato operativo a ciò che compare e costruire una descrizione coerente.
I VLM sono utili in computer vision, document AI, retail, ispezioni, monitoraggio visivo e automazione legata a immagini. Consentono di porre domande sulle immagini, validare anomalie, verificare se un oggetto è presente, se è leggibile, se è integro, se è coerente con il contesto.
Nel caso del riconoscimento della segnaletica stradale da dashcam, un VLM può osservare il frame e aiutare a capire non solo che tipo di segnale è presente, ma anche se è coperto dalla vegetazione, se è ruotato, sbiadito, in ombra o parzialmente nascosto. Nel caso della catalogazione dei pannelli fotovoltaici da drone, il modello può supportare il controllo preliminare: il pannello è davvero visibile? Il barcode è inquadrato? L’immagine è sufficiente per la lettura?
Tra i riferimenti utili sul tema rientrano le pagine di NVIDIA dedicate ai Vision Language Models.
Da ricordare: tra le famiglie di intelligenza artificiale, VLM è il punto di ingresso naturale quando il dato nasce da immagini o video ma deve essere interpretato con il supporto del linguaggio.
Famiglie di intelligenza artificiale leggere: SLM
SLM significa Small Language Models. L’idea alla base è molto concreta: non sempre serve un modello enorme. In molti casi è meglio avere un sistema più leggero, più rapido, più economico e più semplice da eseguire in locale o in ambienti edge.
Tra le famiglie di intelligenza artificiale, questa è particolarmente interessante quando il dato è sensibile, la connettività è limitata o i costi di inferenza devono restare contenuti. Può essere usata da team che vogliono AI sul campo, in mobilità, in officina, in cabina, su drone station, su PC tecnici non connessi sempre al cloud oppure in ambienti dove i dati non devono uscire.
In pratica si parte da architetture più compatte, dataset selezionati, quantizzazione, distillazione e ottimizzazioni per l’inferenza locale. Il vero vantaggio è che possono diventare moduli specifici: classificatore, correttore, compilatore di campi, motore di priorità o assistente locale.
Per il tuo flusso NDVI, uno SLM locale può non essere il cervello che calcola l’indice raster, perché quello resta affidato a Python e librerie geospaziali. Però può spiegare il risultato, generare commenti automatici sul vigore vegetativo, segnalare parcelle anomale e produrre schede testuali senza inviare dati sensibili fuori dalla macchina.
Uno dei riferimenti più espliciti in questo ambito è la famiglia Phi di Microsoft.
Da ricordare: tra le famiglie di intelligenza artificiale, SLM è spesso la scelta migliore quando il compito è stretto, il dato è sensibile e la macchina deve lavorare vicino al campo.
Famiglie di intelligenza artificiale per NLP classico: MLM
MLM significa Masked Language Models. È una famiglia storicamente importantissima. Invece di generare testo in modo autoregressivo come molti LLM moderni, questi modelli imparano spesso a prevedere parole mancanti all’interno di una frase. Questo li rende molto forti nella comprensione contestuale, nella classificazione e nell’estrazione di informazione.
Tra le famiglie di intelligenza artificiale, gli MLM restano molto utili in compiti come Named Entity Recognition, classificazione testuale, ricerca semantica, matching, deduplicazione, estrazione campi da documenti o frasi tecniche. Sono perfetti per chi lavora su NLP più classico e strutturato: archivi, protocolli, document management, email, classificazione ticket, enti con tassonomie o motori di ricerca interni.
Nel contesto Catasto Strade, un MLM può essere molto utile per normalizzare le descrizioni manuali scritte dagli operatori o per classificare automaticamente note testuali storiche. In un archivio agricolo può raggruppare rilievi per categoria di anomalia senza il costo di un grande modello conversazionale.
I riferimenti storici e pratici più importanti restano quelli della famiglia BERT e dei suoi discendenti.
Da ricordare: tra le famiglie di intelligenza artificiale, MLM resta ancora oggi una scelta sobria ed efficiente quando bisogna classificare testi tecnici, note o campi strutturati.
Famiglie di intelligenza artificiale per la segmentazione visiva: SAM
SAM è diventato un nome quasi iconico nella visione artificiale recente. L’idea di fondo è estremamente concreta: segmentare, cioè ritagliare con precisione oggetti o aree di interesse in un’immagine o in un video a partire da prompt visivi o testuali.
Tra le famiglie di intelligenza artificiale, questa è fondamentale quando il primo passo non è classificare ma isolare bene il target. Se vuoi leggere un cartello, un barcode, una targa tecnica, un pannello, una pianta, una chioma o un difetto, spesso conviene prima separare l’oggetto dal resto della scena.
SAM può essere usato da chiunque faccia computer vision pratica: ispezioni, agricoltura di precisione, infrastrutture, medical imaging, cartografia da immagini, droni o produzione industriale. In produzione diventa un eccellente “pre-processore intelligente”.
Nel caso della dashcam e della segnaletica, prima di chiedere a OCR o VLM di leggere un cartello, SAM può isolarlo dal palo, dagli alberi, dal cielo e dal rumore di fondo. Nel caso dei pannelli fotovoltaici da drone, può segmentare i moduli anche con prospettive non perfette, creando ritagli puliti su cui far lavorare lettura barcode, controllo difetti o classificazione.
I riferimenti più noti partono dai rilasci di Meta Segment Anything e dal relativo ecosistema open.
Da ricordare: tra le famiglie di intelligenza artificiale, SAM non basta da solo a riconoscere tutto, ma spesso aumenta moltissimo la qualità di ciò che viene letto o classificato dopo.
Come si combinano in un progetto reale
Famiglie di intelligenza artificiale nel Catasto Strade da dashcam
Acquisizione video con GPS, segmentazione del cartello o del segno, riconoscimento visivo della scena, OCR o detector per i dettagli fini, normalizzazione linguistica della scheda, controllo GIS e dashboard finale. In una pipeline simile, più famiglie di intelligenza artificiale collaborano in sequenza e ciascuna svolge un compito preciso.
Famiglie di intelligenza artificiale nella catalogazione dei pannelli solari da drone
Volo e georeferenziazione, isolamento del modulo, verifica che il target sia leggibile, lettura barcode o seriale, compilazione automatica del catalogo e gestione delle eccezioni con revisione umana. Anche qui il risultato non dipende da un solo modello, ma da una catena ben progettata.
Famiglie di intelligenza artificiale per NDVI, SAVI e indicatori vegetazionali
Calcolo raster in Python con librerie geospaziali, classificazione del vigore con machine learning classico o deep learning, spiegazione testuale del risultato, produzione di mappe, report e priorità di intervento. In questo scenario le famiglie di intelligenza artificiale entrano soprattutto come supporto interpretativo, classificatorio e documentale.
Chi dovrebbe usare quali famiglie di intelligenza artificiale
Un tecnico o una piccola struttura che parte oggi, in genere, fa bene a ragionare così:
- se il problema è soprattutto testuale, conviene partire da LLM o SLM;
- se il problema nasce da foto, video o documenti con immagini, conviene partire da VLM e SAM;
- se il processo deve compiere azioni, bisogna aggiungere un livello LAM o agentico con regole forti;
- se l’obiettivo è classificazione testuale efficiente, vale ancora la pena valutare MLM;
- se si costruisce o si sceglie un foundation model grande, è utile capire se usa architettura MoE;
- se si lavora su ricerca semantica evoluta e concetti, conviene tenere d’occhio LCM.
Errori da evitare
- Pensare che una sola AI risolva tutto da sola.
- Confondere il riconoscimento visivo con la scrittura del report finale.
- Non validare i casi dubbi con soglie e revisione umana.
- Scegliere un modello enorme quando basta un piccolo modello locale.
- Ignorare licenze, privacy, tempi di risposta e costo per inferenza.
- Non progettare bene dataset, logging e controllo qualità.
Conclusioni
La vera maturità, oggi, non sta nel conoscere l’ultima sigla di moda. Sta nel saper comporre bene gli strumenti. Un sistema che riconosce segnaletica da dashcam, legge barcode da drone o commenta automaticamente una mappa NDVI non nasce quasi mai da un solo modello. Nasce da una catena: un occhio che vede, una mano che isola, una mente che interpreta, un linguaggio che spiega e un agente che organizza.
In questo senso, LLM, LCM, LAM, MoE, VLM, SLM, MLM e SAM non sono etichette da collezionare, ma pezzi di una cassetta degli attrezzi. Capire quando usare una o l’altra tra le famiglie di intelligenza artificiale significa progettare meglio, spendere meglio e ottenere risultati più solidi.
- Fonti essenziali e riferimenti ufficiali
- OpenAI API models e documentazione ufficiale
- OpenAI tools e computer use
- Anthropic Claude models
- Anthropic computer use
- Google DeepMind / Gemini models
- Vertex AI model documentation
- Meta Llama
- Meta Large Concept Models
- Repository Large Concept Model
- IBM Mixture of Experts
- IBM Granite
- NVIDIA Vision Language Models
- NVIDIA NIM VLM documentation
- Microsoft Small Language Models
- Microsoft Phi
- Google BERT e masked language modeling
- Meta Segment Anything
- Repository Segment Anything
- Repository SAM 2
- Ultralytics SAM documentation
- Ultralytics SAM 2 documentation
- Ultralytics segmentation tasks
- Mistral AI models
- Mistral AI news
- Browser Use open source
- Microsoft AutoGen
Leggi anche:
- Shopping automatico, AI e collasso del Web
- I migliori Chatbot AI 2025: confronto ChatGPT, Claude, Gemini e altri
- Cherry Studio AI: l’hub desktop per più modelli intelligenti
- SEO e intelligenza artificiale: l’inizio di una nuova era
L'articolo Le otto grandi famiglie di Intelligenza Artificiale proviene da Geosmart Magazine.
-
Incendi emisfero meridionale: inizio 2026 molto critico
19 marzo, di Redazione
Incendi emisfero meridionale gennaio 2026: dati satellitari, FRP record, impatti su salute e clima tra Cile, Argentina e Australia.
Fuoco, atmosfera e satelliti: inizio 2026 critico nell’emisfero meridionale
Un inizio anno infuocato per i Paesi dell’emisfero Sud del nostro Pianeta, che si sono trovati ad affrontare un numero eccezionalmente elevato di incendi boschivi a seguito delle temperature record registrate durante questo caldo gennaio. I dati del Copernicus Atmosphere Monitoring Service (CAMS), derivati dall’integrazione di osservazioni satellitari e modelli atmosferici, hanno rivelato un’intensa attività di incendi in diverse regioni di Cile, Argentina e Australia.
Il monitoraggio è stato possibile grazie a sensori satellitari dedicati all’osservazione atmosferica e termica, tra cui quelli della costellazione Copernicus. In particolare, i satelliti Sentinel-3 e i sensori MODIS e VIIRS sono utilizzati per il rilevamento diretto dei focolai attivi, mentre Sentinel-4 e Sentinel-5 contribuiscono al monitoraggio della composizione atmosferica e degli inquinanti prodotti dagli incendi.
Cile: tra record e stato di catastrofe
In Cile si contano almeno 21 vittime e circa 50.000 persone evacuate nelle regioni di Ñuble e Biobío, nel sud del Paese. La Fire Radiative Power (FRP) (indicatore della potenza radiativa emessa dagli incendi e che è proporzionale sia alla temperatura delle fiamme sia alla quantità di biomassa in combustione) ha raggiunto valori fino a 24 volte superiori alla media del periodo 2003–2025. Valori così elevati hanno spinto il presidente della Repubblica del Cile, Gabriel Boric, a dichiarare lo stato di catastrofe nazionale. Complessivamente, circa 42.000 ettari di superficie boscata, l’equivalente di oltre 59.000 campi da calcio, sono andati distrutti. Gli incendi si sono sviluppati in un’area già fortemente stressata da anni di siccità persistente, con una marcata carenza di precipitazioni e temperature che hanno raggiunto i 37 °C, condizioni ideali per la propagazione del fuoco.
Incendi emisfero meridionale anche in Argentina
Una situazione analoga si è verificata nella vicina Argentina, dove circa 32.000 ettari di bosco sono stati incendiati, con valori di FRP fino a 13 volte superiori alla media 2003–2025 per lo stesso periodo. Anche in questo caso, la combinazione di siccità prolungata, temperature elevate e forti venti, hanno favorito la rapida espansione degli incendi, ben visibile nelle sequenze temporali di immagini satellitari.
La lista si allunga: anche l’Australia è colpita dagli incendi
Non è da meno l’Australia, storicamente esposta a incendi boschivi di grande intensità. Già nel biennio 2019-2020, un evento senza precedenti ha colpito il Paese, bruciando oltre 30 milioni di ettari e generando una nube di fumo che ha interessato aree urbane come Sydney, con effetti misurabili anche a scala emisferica. All’inizio del 2026, un incendio di dimensioni relativamente più contenute, ma comunque significativo, ha interessato circa 400.000 ettari nello Stato di Victoria, nel sud-est del Paese, causando una vittima e la distruzione di circa 900 edifici. Anche in questo caso, le temperature prossime ai 40 °C, rilevate e confermate dai dati satellitari e meteorologici, hanno favorito la rapida propagazione delle fiamme. Per motivi di sicurezza pubblica, eventi di grande rilevanza come le celebrazioni dell’Australia Day del 26 gennaio sono stati annullati.
Nel video, pubblicato dal CAMS, si può osservare l’evoluzione degli incendi boschivi nel Gennaio del 2026 e il trasporto di polveri sottili su scala regionale e intercontinentale. Le aree in violetto indicano le zone dove gli incendi sono più potenti e dunque dove c’è una maggiore concentrazione di fumi e inquinanti. Nel tempo, si osserva la dispersione dei fumi, che possono raggiungere migliaia di chilometri di distanza dall’origine e la loro persistenza nel tempo. La visualizzazione satellitare mostra l’evoluzione temporale degli incendi e la dispersione del fumo nell’atmosfera, evidenziando come eventi locali possano avere effetti su scala regionale e globale grazie al trasporto atmosferico.
Impatti sulla salute: il ruolo del PM2.5
Il monitoraggio degli incendi, sia a scala locale sia globale, è fondamentale per le gravi ripercussioni sulla salute umana. Un recente studio di Hao et al., pubblicato il 27 gennaio sulla rivista European Heart Journal, ha evidenziato come gli effetti degli incendi boschivi possano manifestarsi anche a migliaia di chilometri di distanza dalla sorgente. Il particolato fine PM2.5, costituito da particelle con diametro inferiore o uguale a 2,5 micrometri (un micrometro corrisponde a un millesimo di millimetro), può causare, anche per esposizioni brevi, irritazioni delle vie respiratorie. Tuttavia, un’esposizione prolungata, come quella associata a vasti incendi persistenti, può determinare crisi asmatiche, aumento del rischio cardiovascolare e compromissione del sistema cardiocircolatorio.
È quindi fondamentale monitorare l’estensione spaziale, la temperatura e l’evoluzione temporale degli incendi boschivi. Il Copernicus Atmosphere Monitoring Service utilizza il Global Fire Assimilation System (GFAS), che assimila quotidianamente osservazioni satellitari di FRP per stimare le emissioni di carbonio e aerosol e per prevedere la dispersione del fumo e l’evoluzione degli incendi fino a cinque giorni successivi.
Tecnologia e resilienza climatica
Gli incendi boschivi che hanno colpito l’emisfero meridionale nel gennaio 2026 non rappresentano solo un chiaro segnale della crescente pressione climatica su ecosistemi già vulnerabili, ma costituiscono anche una dimostrazione concreta del ruolo strategico delle tecnologie geospaziali. Dalla rilevazione in tempo quasi reale dei focolai, alla stima delle emissioni, fino alla previsione del trasporto degli inquinanti su scala regionale e globale, i satelliti e sistemi come GFAS si confermano strumenti essenziali non solo per comprendere questi eventi estremi ma anche per mitigarne gli impatti su società, salute e ambiente.
Articolo di Carmine Magri
(Fonte: Copernicus)
Leggi anche:
- Bruciatura delle stoppie agricole e incendi: norme, rischi e soluzioni
- Incendi estate 2025: l’Europa e il mondo in fiamme
- Incendio boschivo in Canada: il fumo arriva fino al Mediterraneo
- Guida ai prodotti Copernicus per incendi boschivi e ambiente
L'articolo Incendi emisfero meridionale: inizio 2026 molto critico proviene da Geosmart Magazine.
-
Google Photorealistic 3D maps su ArcGIS Online: questo cambia tutto!
18 marzo, di Silvia IlacquaLe Google photorealistic 3D maps approdano su ArcGIS online, rivoluzionando completamente il modo di vedere ed usare i GIS.
Se lavori con il GIS e ami il 3D, probabilmente questa è una di quelle notizie che ti fanno sorridere davanti allo schermo o saltare sulla sedia, cosi come è accaduto alla sottoscritta, quando tra una sessione di lavoro e l’altra si è trovata davanti questa notizia.
Ora, immagina di aprire una scena 3D in ArcGIS Online, aggiungere una basemap… e trovarti davanti una città intera ricostruita in tre dimensioni, con edifici, strade e morfologia urbana riprodotti in modo incredibilmente realistico. Ecco ora non dovrai immaginarlo più, perché è completamente possibile.
Non sto parlando di impronte di edifici estrusi, modelli semplificati, forme geometriche stilizzato. Ma di una vera mesh tridimensionale fotorealistica del mondo reale.
L’ecosistema GIS si arricchisce con il 3D
È esattamente quello che succede oggi grazie all’arrivo delle Google Photorealistic 3D Basemaps, che portano dentro l’ecosistema GIS una delle ricostruzioni tridimensionali del pianeta più avanzate mai realizzate. Ma questa novità non è comparsa dal nulla.
È il risultato di un percorso iniziato circa un anno fa e costruito attraverso una serie di passaggi chiave che hanno progressivamente avvicinato il mondo di Esri e quello di Google. Ripercorriamo insieme, in breve, l’incredibile percorso che in meno di un anno dal suo primo annuncio ha portato ad una democratizzazione del dato 3D.Il primo segnale arriva il 10 marzo 2025, quando durante la Esri Partner Conference viene annunciata ufficialmente la collaborazione tra Esri e Google Maps Platform.
L’obiettivo è stato ufficializzato e chiarito fin da subito: portare all’interno della piattaforma ArcGIS i Photorealistic 3D Tiles di Google, consentendo alla comunità GIS di utilizzare una rappresentazione tridimensionale estremamente realistica del mondo reale come contesto per analisi, applicazioni e visualizzazioni geospaziali.
I dataset sviluppati da Google includono modelli tridimensionali ottenuti da immagini aeree e tecniche avanzate di ricostruzione fotogrammetrica. Il risultato è una rappresentazione continua delle città, capace di descrivere edifici, infrastrutture e morfologie urbane con un livello di dettaglio molto elevato. Già all’epoca dell’annuncio si parlava di una copertura impressionante: oltre 2.500 città distribuite in circa 49 paesi.
ArcGIS pro 3.6 x Google photorealistic 3D maps
Durante il 2025 la tecnologia inizia a comparire progressivamente nell’ecosistema ArcGIS.
Nel secondo trimestre dell’anno gli utenti più curiosi e tecnici potevano già sperimentarla tramite API di Google all’interno di ArcGIS Pro 3.5, integrando manualmente le 3D Mesh nelle scene 3D. Un playground perfetto per i più nerd del GIS, che potevano già intuire le potenzialità di questo nuovo livello di realismo.
A fine 2025 arriva un passo importante: con ArcGIS Pro 3.6 le Google Photorealistic 3D Tiles diventano accessibili direttamente nell’ambiente desktop, entrando a far parte del workflow 3D della piattaforma.
Ma il vero salto di scala arriva nel 2026
Con il rilascio ufficiale su ArcGIS Online, le mesh tridimensionali diventano finalmente disponibili direttamente nella Basemap Gallery, pronte per essere utilizzate nelle scene web senza configurazioni particolari. Questo cambia tutto.
Cambia soprattutto il modo di fruire del dato 3D. La sua implementazione nel GIS Online di Esri amplifica ulteriormente non solo il suo valore nelle analisi geospaziali, ma anche il suo valore come strumento dal forte impatto comunicativo. Questo supera qualsiasi sforzo di astrazione necessario e porta l’utente in una dimensione che potremmo quasi definire di realtà virtuale.
Ripercorriamo per punti l’evoluzione che ha portato fino ad oggi:
• Marzo 2025 – Esri annuncia la partnership con Google Maps Platform per l’implementazione delle Google Photorealistic 3D
• Maggio 2025 – Le 3D Tiles diventano accessibili tramite API in ArcGIS Pro 3.5
• Fine 2025 – Arriva la beta della basemap 3D fotorealistica direttamente dentro ArcGIS Pro 3.6
• Marzo 2026 – Le Google Photorealistic 3D Basemaps arrivano ufficialmente su ArcGIS Online
Come Google costruisce le città 3D fotorealistiche
Dietro queste basemap c’è un processo tecnologico molto sofisticato. Le Google Photorealistic 3D Basemaps sono il risultato della combinazione di acquisizione massiva di immagini aeree, fotogrammetria automatizzata e modellazione 3D su larga scala. Il processo parte dalla raccolta di enormi quantità di immagini aeree ad alta risoluzione, spesso acquisite con fotografie oblique. Questo tipo di immagini permette di catturare non solo i tetti degli edifici ma anche le loro facciate. Le immagini vengono poi elaborate tramite algoritmi di fotogrammetria come Structure from Motion e Multi‑View Stereo, che consentono di ricostruire la geometria tridimensionale delle città generando una dense point cloud. Da questa nuvola di punti viene poi creata una mesh tridimensionale continua, sulla quale vengono proiettate le texture fotografiche originali per ottenere il risultato fotorealistico.
Google photorealistic 3D maps: perché si parla di 3D Tiles
C’è un problema però che conosco bene tutti coloro che lavorano nel settore della reality capture. Ovvero, lo sforzo computazionale e di memoria che un modello 3D necessita. Un modello tridimensionale di una città può pesare centinaia di gigabyte, per questo viene utilizzato lo standard 3D Tiles, pensato per lo streaming di grandi dataset tridimensionali. Il modello viene suddiviso in piccoli blocchi chiamati tiles, caricati dinamicamente mentre l’utente naviga la scena. In questo modo solo le parti necessarie vengono scaricate e visualizzate, mantenendo fluida l’esplorazione anche di città molto estese.
Non una nuova dimensione per il GIS, ma una nuova percezione
Per anni il GIS ha raccontato il territorio soprattutto attraverso mappe bidimensionali, poi ha iniziato ad abbracciare sempre di più il tridimensionale, sposando la sua tecnologia geospaziale con quella ingegneristica del BIM e del Digital Twin. Ma nonostante ciò, per molto tempo la terza dimensione è continuata a rimanere prerogativa dei grandi studi di progetti di reality capture.
Oggi però qualcosa sta cambiando. Con l’arrivo delle mesh fotorealistiche globali, la cartografia digitale si avvicina sempre di più a una rappresentazione immersiva dello spazio reale e ad una democratizzazione del dato tridimensionale.
Non è solo una questione estetica, ma anche comunicativa. Avere città tridimensionali realistiche come basemap significa poter comprendere meglio il rapporto tra dati, spazio e infrastrutture. Comunicare al meglio i rischi e i bisogni di un territorio. Comunicare i fenomeni complessi in modo più immediato. Stiamo iniziando a osservare il pianeta attraverso una nuova interfaccia geografica che ha l’obiettivo di portare il virtuale sempre più a servizio del reale.
(Articolo di Silvia Ilacqua)
Bibliografia:
Leggi anche:
- Arriva la Photorealistic 3D Basemap grazie ad Esri e Google
- ArcGIS Knowledge Graph: un modo diverso di studiare il territorio
- Conferenza Esri Italia 2026: innovazione per guidare il futuro
- BIM Workflow e collaborazione: gestire e condividere dati di progetto
L'articolo Google Photorealistic 3D maps su ArcGIS Online: questo cambia tutto! proviene da Geosmart Magazine.
-
Modelli climatici: l’estate che verrà
18 marzo, di RedazioneModelli climatici NEX-GDDP-CMIP6 NASA: analisi dei giorni estremamente secchi e piovosi in Italia per valutare siccità e rischio idrogeologico.
Hotspot del Mediterraneo
Il bacino del Mediterraneo è riconosciuto dalla comunità scientifica https://esd.copernicus.org/articles/13/321/2022/ come uno dei principali climate change hotspot a scala globale. In questa regione, il riscaldamento globale non si manifesta solo attraverso un aumento delle temperature medie, ma soprattutto tramite una crescente estremizzazione del ciclo idrologico, con estati progressivamente più secche intervallate da episodi di precipitazione breve ma intense. Nel contesto italiano, questa dinamica si traduce in una co-esistenza di siccità prolungate e piogge estreme, spesso concentrate in pochi giorni. L’aumento della frequenza dei giorni estremamente secchi durante l’estate contribuisce ad accentuare lo stress idrico su ecosistemi, agricoltura e risorse idriche, mentre la presenza di eventi estremamente piovosi, anche se meno frequenti, incrementa il rischio di alluvioni improvvise, frane ed erosione del suolo, soprattutto in territori orograficamente complessi e urbanizzati.
Proiezioni da modelli climatici
Le proiezioni climatiche ad alta risoluzione, come quelle fornite dai modelli NEX-GDDP-CMIP6 (NASA Earth eXchange Global Daily Downscaled Projections – Coupled Model Intercomparison Project Phase 6) https://developers.google.com/earth-engine/datasets/catalog/NASA_GDDP-CMIP6?hl=it#description permettono di analizzare non solo le variazioni totali delle precipitazioni, ma anche i cambiamenti nella distribuzione degli eventi estremi, un aspetto cruciale per la pianificazione dell’adattamento climatico. In questo senso, la combinazione di indicatori di eventi estremamente secchi e piovosi rappresenta uno strumento utile per supportare strategie di gestione del rischio climatico, in particolare nei settori della protezione civile, della gestione delle risorse idriche e della prevenzione degli incendi boschivi.
Modelli climatici: gli scenari degli eventi estremi
Gli scenari degli eventi di precipitazione estremamente scarse e delle precipitazioni estremamente intense (vedi mappe) durante la stagione estiva (giugno–luglio–agosto, JJA) per il periodo 2020-2026 sono stati elaborati utilizzando i dati climatici giornalieri NEX-GDDP-CMIP6, con una risoluzione spaziale di 0,25° × 0,25°, nell’ambito delle attività formative del NASA Applied Remote Sensing Training Program (ARSET) https://www.earthdata.nasa.gov/learn/trainings/assessing-extreme-weather-statistics-using-nasa-earth-exchange-global-daily . Questi eventi sono stati identificati applicando il 10° e il 90° percentile alle precipitazioni giornaliere estive dell’intero periodo di riferimento: un giorno viene classificato come estremamente secco e piovoso quando il valore di precipitazione giornaliera risulta inferiore (secco) e superiore (piovoso) a tale soglia. Per ogni cella di griglia sono rappresentati il numero medio di giorni estremamente secchi e piovosi per estate, evidenziando le aree maggiormente esposte a condizioni di deficit pluviometrico persistente e aree in cui si concentra una maggiore frequenza di eventi intensi, potenzialmente associati a allagamenti, dissesto idrogeologico ed erosione del suolo. I grafici mostrano l’andamento temporale della frequenza media dei giorni estremamente secchi (precipitazione < 10° percentile) e l’evoluzione temporale della frequenza dei giorni con precipitazioni estremamente intense (precipitazione > 90° percentile) sempre per il periodo 2020-2026 e consente di valutare la variabilità interannuale degli eventi di siccità estiva e l’eventuale presenza di tendenze, nonché l’aumento o la diminuzione della frequenza degli eventi estremi, offrendo informazioni complementari utili per il confronto tra anni consecutivi. Si badi che quanto si osserva nelle mappe degli eventi (giorni estremamente secchi e intensamente piovosi) non è una previsione meteorologica, ma l’orizzonte finale di una proiezione climatica a breve termine, una stima statistica del comportamento atteso di uno specifico scenario di eventi estremi/intensi (secco e umido) ed è un riferimento utile per valutare tendenze e segnali emergenti, ma non singoli eventi reali.
Dagli scenari climatici agli strumenti operativi
Dal punto di vista climatologico, gli indicatori analizzati risultano particolarmente rilevanti per la valutazione del potenziale stress idrico, della siccità agricola e dell’aumento del rischio di incendi boschivi e/o vegetazionali, soprattutto nei contesti del Sud Italia, dove gli ultimi anni sono stati caratterizzati da una crescente stagionalità delle precipitazioni estive. In queste aree, periodi prolungati di assenza di pioggia tendono sempre più spesso ad alternarsi a episodi di precipitazione intensa e concentrata, con effetti significativi sugli ecosistemi, sulla gestione del territorio, ma soprattutto sulle riserve idriche. In questo quadro si inserisce il progetto WebGIS open data “SiccITàLY” https://www.satmonitoring.it/webgis , che mira a integrare indicatori climatici e ambientali derivati da dati satellitari e modelli climatici, con l’obiettivo di fornire una lettura spazio-temporale coerente dei fenomeni di siccità e degli estremi idro-climatici. L’analisi congiunta della frequenza dei giorni estremamente secchi e di quelli estremamente piovosi consente infatti di cogliere non solo le variazioni nei totali di pioggia, ma soprattutto i cambiamenti nella distribuzione e nell’intensità degli eventi, aspetti chiave nella valutazione degli impatti dei cambiamenti climatici nell’intero bacino mediterraneo.
Articolo di Vito L’Erario
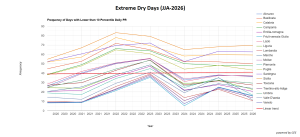
Analisi dei giorni estremamente secchi. 
Analisi dei giorni piovosi. Leggi anche:
- Bruciatura delle stoppie agricole e incendi: norme, rischi e soluzioni
- Incendi a Los Angeles: danni ai centri per Earth Observation
- La siccità in Italia meridionale monitorata dai satelliti Copernicus
- Siccità in Sardegna: le immagini Copernicus del Lago Omodeo
L'articolo Modelli climatici: l’estate che verrà proviene da Geosmart Magazine.